Общие принципы функционирования СУБД
Понимание внутреннего устройства СУБД необходимо для написания эффективных запросов и правильной эксплуатации системы. Современные промышленные СУБД (PostgreSQL, Oracle, SQL Server) функционируют на основе архитектуры «Клиент-Сервер».
Архитектура «Клиент-Сервер» в контексте СУБД
В отличие от настольных систем прошлого (например, Microsoft Access или FoxPro), где приложение напрямую читало файлы базы данных с жесткого диска, промышленные СУБД реализуют строгое разделение ответственности.
Определение
Архитектура «Клиент-Сервер» в базах данных подразумевает наличие двух независимых программных компонентов:
- Сервер СУБД: Процесс (или группа процессов), который управляет данными, обеспечивает их целостность, безопасность и выполняет вычисления. Он имеет монопольный доступ к файлам базы данных на диске.
- Клиент: Приложение, которое формирует запрос к серверу и ожидает ответа. Клиент никогда не работает с файлами данных напрямую.
Физическое и логическое взаимодействие
Взаимодействие строится по схеме «Запрос — Ответ» (Request — Response):
- Инициализация: Клиент инициирует соединение с сервером (Handshake), проходя аутентификацию (Логин/Пароль).
- Запрос: Клиент отправляет команду на языке SQL (например,
SELECT * FROM users). Это текстовая строка. - Обработка: Сервер принимает запрос, парсит его, планирует выполнение, читает данные с диска, фильтрует их и формирует результат.
- Ответ: Сервер отправляет клиенту Result Set (набор данных) — фактически, таблицу с результатами или код подтверждения операции.
Важное уточнение
В современной веб-разработке под термином «Клиент СУБД», как правило, понимается Backend-сервер (написанный на Node.js, Python, Java, PHP), а не браузер конечного пользователя. Браузер отправляет HTTP-запрос на Бэкенд, а Бэкенд, выступая в роли клиента, отправляет SQL-запрос в Базу Данных.
Сетевое взаимодействие
Физически клиент и сервер могут находиться как на одной машине, так и на разных континентах. Взаимодействие осуществляется через сетевые интерфейсы.
Сокеты (Sockets):
- Unix Domain Socket: Используется, если клиент и сервер находятся на одном компьютере (Linux/Unix). Это самый быстрый способ, работающий через файловую систему (как специальный файл
.s.PGSQL.5432). - TCP/IP Socket: Стандартный способ взаимодействия по сети. Сервер «слушает» определенный порт (по умолчанию для PostgreSQL —
5432, для MySQL —3306), ожидая входящих подключений.
- Unix Domain Socket: Используется, если клиент и сервер находятся на одном компьютере (Linux/Unix). Это самый быстрый способ, работающий через файловую систему (как специальный файл
Протокол: СУБД используют собственные бинарные протоколы прикладного уровня (не HTTP). Например, PostgreSQL Wire Protocol. Он оптимизирован для передачи структурированных данных, поддерживает состояние сессии и транзакции.
Пропускная способность и задержки («Толстый» канал)
Сетевая среда накладывает физические ограничения на работу базы данных. Инженер должен учитывать два фактора:
- Latency (Задержка): Время, необходимое сигналу, чтобы дойти от клиента к серверу и обратно (RTT — Round Trip Time).
- Проблема: Если приложение делает 1000 последовательных простых запросов (N+1 проблема), и пинг до базы составляет 10 мс, то суммарное время выполнения составит 10 секунд, даже если сама база выполняет запросы мгновенно.
- Throughput (Пропускная способность): Объем данных, который можно передать за единицу времени.
- Проблема: Запрос
SELECT *к таблице с миллионом строк может «забить» сетевой канал. Сервер базы данных прочитает данные быстро, но передача гигабайтов текста по сети займет минуты.
- Проблема: Запрос
"Узкое место" (Bottleneck)
Сеть часто является самым медленным компонентом системы. Оптимизация запросов часто сводится не к ускорению чтения диска, а к уменьшению объема передаваемых данных. Правило: "Возвращай на клиента только те данные, которые ему действительно нужны прямо сейчас".
Разделение понятий: Экземпляр (Instance) и База Данных (Database)
В профессиональной терминологии администраторов баз данных (DBA) существует строгое различие между понятиями «База данных» и «Экземпляр», хотя в разговорной речи их часто смешивают. Понимание этого различия необходимо для диагностики проблем запуска и производительности.
База Данных (Database) — Физический уровень
База данных — это набор файлов, хранящихся на дисковом массиве. Это пассивное хранилище информации.
- Состав: Файлы данных (где лежат таблицы), файлы индексов, журналы транзакций (WAL), файлы конфигурации (
postgresql.conf,pg_hba.conf) и контрольные файлы. - Состояние: Может существовать без запущенного программного обеспечения. Например, когда сервер выключен, «база данных» продолжает существовать на диске как набор байтов.
- Локация: В PostgreSQL все эти файлы обычно располагаются в директории данных, именуемой
PGDATA(например,/var/lib/postgresql/data).
Аналогия
База данных — это книги в библиотеке. Они стоят на полках (диске) даже ночью, когда библиотека закрыта. Сами по себе книги ничего не делают и никому не отвечают.
Экземпляр (Instance) — Логический (Оперативный) уровень
Экземпляр — это совокупность процессов операционной системы и выделенных структур оперативной памяти (RAM), которые взаимодействуют с файлами базы данных. Это «движок», который оживляет данные.
- Состав:
- Фоновые процессы: Главный процесс (Postmaster), процессы записи (Background Writer), очистки (Autovacuum) и др.
- Разделяемая память (Shared Memory): Область RAM, доступная всем процессам СУБД (кэши данных, буферы журналов, таблицы блокировок).
- Функция: Экземпляр «поднимает» данные с холодного диска в горячую память, обрабатывает запросы клиентов и обеспечивает транзакционную целостность.
Аналогия
Экземпляр — это персонал библиотеки и читальный зал. Библиотекари (процессы) берут книги (файлы) с полок и приносят их в читальный зал (память), где с ними работают читатели (клиенты). Без персонала книги недоступны.
Взаимодействие
Клиентское приложение никогда не взаимодействует с файлами базы данных напрямую.
- Клиент подключается к Экземпляру (сетевому порту).
- Экземпляр проверяет, есть ли нужные данные в Памяти (Cache Hit).
- Если нет — Экземпляр считывает блоки из Базы Данных (Диск) в Память.
- Клиент получает ответ из Памяти.
Важность различия
Если «упал экземпляр» (crahsed instance) — это сбой программного обеспечения, данные на диске скорее всего целы, нужен перезапуск службы. Если «повреждена база данных» (corrupted database) — это физическое повреждение файлов (битые сектора диска), требующее восстановления из резервной копии.
Процессная модель (на примере PostgreSQL)
В отличие от многих других СУБД (например, MySQL или MS SQL Server), которые используют многопоточную архитектуру (Multi-threaded), PostgreSQL построен на многопроцессной архитектуре (Multi-process). Это фундаментальное архитектурное решение определяет надежность, принципы масштабирования и специфику работы с соединениями.
Главный процесс: Postmaster (Supervisor)
При старте службы PostgreSQL операционная система запускает один единственный процесс, исторически называемый Postmaster (в современных версиях в списке процессов он может отображаться просто как postgres).
Функции Postmaster:
- Инициализация: Выделяет область разделяемой памяти (Shared Memory) и запускает фоновые процессы.
- Сетевой лиснер: Слушает порт (по умолчанию
5432) и ожидает входящих пакетов на установку соединения. - Арбитраж и восстановление: Следит за здоровьем всей системы. Если один из дочерних процессов аварийно падает (например, с ошибкой
SEGFAULT), Postmaster инициирует процедуру Recovery: принудительно завершает всех остальных, чистит общую память и перезапускает систему, чтобы избежать повреждения данных.
Аналогия
Postmaster — это администратор на ресепшене отеля. Он не носит чемоданы и не убирает номера. Он только встречает гостей, выдает ключи и следит, чтобы отель не сгорел.
Клиентские процессы (Backend Processes)
PostgreSQL реализует модель «Один процесс на одно соединение» (Process-per-connection).
Алгоритм подключения:
- Клиент стучится в порт 5432.
- Postmaster принимает соединение, проводит базовый хендшейк.
- Postmaster делает системный вызов
fork(). - Операционная система создает полную копию процесса Postmaster.
- Новый процесс (называемый Backend Process или
postgres: user dbname ip) берет на себя обслуживание именно этого клиента. - Postmaster возвращается к прослушиванию порта, а Клиент и Бэкенд общаются напрямую.
Если вы запустите команду ps aux | grep postgres или htop на нагруженном сервере, вы увидите сотни процессов postgres. Это и есть активные сессии.
Почему создание соединения — дорогая операция?
В веб-разработке часто совершается ошибка: приложение открывает соединение, делает один запрос SELECT и закрывает соединение. В мире PostgreSQL это считается антипаттерном из-за высокой стоимости создания процесса (Overhead).
Из чего складывается «цена» подключения:
- Операционная система (Kernel Space):
- Вызов
fork()требует копирования таблицы страниц памяти родительского процесса. Несмотря на механизм Copy-On-Write (COW), это затратная операция для CPU. - Выделение PID и структур ядра.
- Вызов
- Инициализация СУБД (User Space):
- Аллокация локальной памяти процесса (
work_mem, кэши каталога). - Инициализация доступа к разделяемой памяти.
- Аутентификация (проверка пароля, SSL-хендшейк, проверка правил
pg_hba.conf).
- Аллокация локальной памяти процесса (
- Сетевые задержки:
- Тройное рукопожатие TCP/IP.
Проблема масштабируемости
Если 1000 клиентов одновременно попытаются подключиться к базе, сервер потратит все ресурсы процессора не на выполнение SQL-запросов, а на «форканье» процессов. При этом каждый процесс отъедает кусок оперативной памяти (минимум 2-5 МБ), что при большом количестве коннектов может привести к OOM (Out Of Memory).
Решение: Для борьбы с этим используются пулеры соединений (Connection Poolers), такие как PgBouncer или Odyssey. Они держат постоянные открытые соединения с базой (например, 50 штук) и мгновенно выдают их клиентам, избавляя базу от необходимости делать fork() на каждый чих.
Управление памятью (Shared Memory)
Эффективность работы СУБД на 90% зависит от того, насколько грамотно она работает с оперативной памятью. Дисковые операции (I/O) — это самая медленная часть системы (даже с NVMe SSD), поэтому задача СУБД — минимизировать походы на диск.
В архитектуре PostgreSQL память делится на две большие зоны: Глобальную (Shared) и Локальную (Local).
Shared Buffers (Разделяемый буферный кэш)
Это общая область памяти, доступная всем процессам экземпляра одновременно. Она выделяется при старте сервера (параметр shared_buffers).
- Принцип работы: База данных работает с данными только в памяти. Нельзя прочитать или изменить строку прямо на диске.
- Если клиент запрашивает строку, Postgres ищет страницу (блок 8кб), содержащую эту строку, в Shared Buffers.
- Если страница там есть (Cache Hit) — данные отдаются мгновенно.
- Если страницы нет (Cache Miss) — процесс идет на диск, читает блок, кладет его в Shared Buffers, и только потом отдает клиенту.
- Грязные страницы (Dirty Pages): Когда вы делаете
UPDATE, данные меняются только в памяти (в Shared Buffers). На диск они сбрасываются позже фоновым процессом (Background Writer) или при Checkpoint. Это позволяет не тормозить запись.
Локальная память процессов (Local Memory)
Каждый Backend-процесс, обслуживающий клиента, запрашивает у ОС личную память для выполнения операций с данными.
work_mem: Ключевой параметр. Это память, используемая для операций сортировки (ORDER BY), группировки (GROUP BY DISTINCT) и хэширования (Hash Join).maintenance_work_mem: Память для служебных операций (создание индексов,VACUUM).temp_buffers: Буфер для хранения временных таблиц (TEMPORARY TABLES). Поскольку временные таблицы видит только одна сессия, их нет смысла класть в общую память (Shared Buffers). Это ускоряет работу, так как не требует блокировок и сложного журналирования.
Опасность OOM (Out Of Memory)
Параметр work_mem задается не на все соединение, а на одну операцию внутри запроса. Если вы выставили work_mem = 100MB, а в сложном запросе 5 узлов сортировки и 5 соединений, то один запрос может съесть 100MB * 10 = 1GB памяти. Умножьте это на 50 активных клиентов — и сервер "упадет" от нехватки памяти.
Жизненный цикл SQL-запроса (Pipeline обработки)
Когда сервер получает строку с SQL-кодом, она проходит сложный конвейер превращения из текста в бинарные операции над файлами. Понимание этого пути помогает оптимизировать запросы.
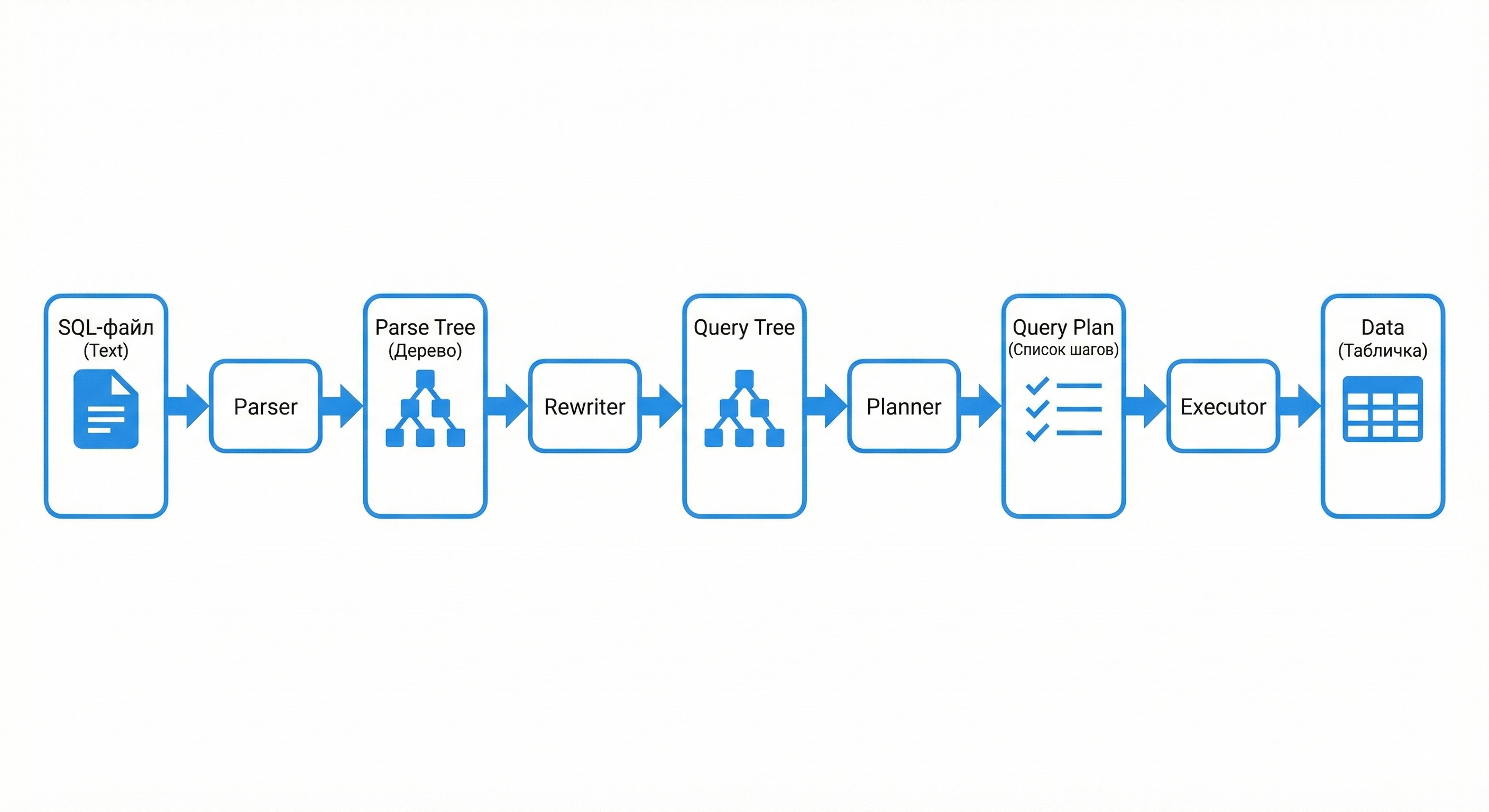
Этап 1. Парсер (Parser) — Лексический и синтаксический анализ
На этом этапе СУБД проверяет валидность синтаксиса.
- Разбивает текст на токены (ключевые слова, идентификаторы, литералы).
- Строит Дерево разбора (Parse Tree).
- Результат: Если вы напишете
SELEKTвместоSELECT, ошибка возникнет именно здесь. База еще не знает, существуют ли таблицы, она проверяет только грамматику SQL.
Этап 2. Переписыватель (Rewriter / Analyzer)
Здесь происходит семантический анализ и трансформация дерева.
- Проверка существования: СУБД смотрит в системный каталог: существует ли таблица
users? Есть ли у нее колонкаemail? Хватит ли прав у пользователя? - Раскрытие VIEW (Представлений): Если запрос идет к представлению (
View), Rewriter подменяет имя представления на реальный подзапрос, который в нем зашит. - Результат: Дерево запроса (Query Tree), полностью готовое к планированию.
Этап 3. Планировщик (Query Planner / Optimizer) — Мозг системы
Самый сложный и интеллектуальный модуль. Его задача — найти самый дешевый способ выполнить запрос. Один и тот же результат можно получить разными путями:
- Прочитать всю таблицу (Seq Scan) или использовать индекс (Index Scan)?
- Соединить таблицы вложенным циклом (Nested Loop) или через хэш (Hash Join)?
Планировщик рассчитывает Cost (Стоимость) для каждого варианта, основываясь на статистике (сколько строк в таблице, как они распределены).
- Результат: План выполнения (Query Plan) — инструкция для исполнителя.
EXPLAIN
Команда EXPLAIN в SQL показывает именно результат работы Планировщика — то, как база собирается выполнять ваш запрос.
Этап 4. Исполнитель (Executor)
"Рабочая лошадка", которая не думает, а делает.
- Он берет План выполнения и рекурсивно проходит по его узлам.
- Обращается к подсистеме памяти (Shared Buffers) за страницами данных.
- Фильтрует строки, сортирует их в
work_mem. - Результат: Передача клиенту итогового набора строк (Result Set).
Фоновые процессы (Background Workers)
Помимо процессов, обслуживающих клиентские соединения, в системе постоянно функционирует группа служебных (фоновых) процессов. Они запускаются автоматически при старте экземпляра и выполняют регламентные работы, необходимые для поддержания жизнеспособности базы данных.
1. Background Writer (Writer) — Сглаживание нагрузки
В PostgreSQL данные изменяются сначала в оперативной памяти (в Shared Buffers). Страницы памяти, данные в которых были изменены, но еще не записаны на диск, называются «грязными» страницами (Dirty Pages).
Если записывать каждую страницу на диск мгновенно при изменении, производительность упадет до уровня скорости HDD/SSD. Поэтому запись происходит отложенно.
Задача Writer: Фоновый процесс просыпается с заданной периодичностью, сканирует буферный кэш, находит «грязные» страницы и плавно сбрасывает их на диск.
- Зачем это нужно: Чтобы облегчить работу процессу Checkpointer (Контрольная точка). Если Writer не будет работать, то во время контрольной точки системе придется сбрасывать на диск гигабайты данных разом, что приведет к фризу (зависанию) ввода-вывода (I/O Spike). Writer «размазывает» эту нагрузку во времени.
2. WAL Writer (WalWriter) — Гарант сохранности
Этот процесс отвечает за надежность (Durability). Он переносит данные из буферов журнала транзакций (WAL Buffers в RAM) в файлы журнала на диске (WAL-файлы).
- Принцип работы: WAL Writer обеспечивает запись журнала на диск с определенным интервалом (по умолчанию каждые 200 мс), даже если транзакция еще не завершена. Это гарантирует, что в случае внезапного отключения питания мы потеряем минимум данных.
3. Autovacuum Launcher & Workers — Сборщик мусора
Самый важный и обсуждаемый фоновый процесс в PostgreSQL, работа которого обусловлена механизмом MVCC (Multi-Version Concurrency Control).
Проблема "мертвых душ" (Dead Tuples)
В PostgreSQL при операции DELETE строка не удаляется физически, а лишь помечается как «мертвая» (невидимая для новых транзакций). При операции UPDATE создается новая версия строки, а старая также помечается как «мертвая». Если эти старые версии не чистить, таблицы раздуваются (Bloat), занимая все место на диске, а индексы начинают тормозить.
Задачи Autovacuum:
- Очистка (Vacuum): Находит страницы с «мертвыми» строками и помечает пространство как свободное для повторного использования (перезаписи).
- Сбор статистики (Analyze): Обновляет метаданные о распределении данных в таблицах. Эта статистика критически важна для Планировщика запросов. Если Autovacuum не прошел, планировщик будет думать, что в таблице 0 строк, хотя их миллион, и выберет катастрофически неверный план выполнения.
- Защита от переполнения счетчика транзакций (Anti-Wraparound): Предотвращает ситуацию, когда база данных блокируется из-за исчерпания 32-битных идентификаторов транзакций (XID).
Миф об Autovacuum
Многие начинающие администраторы пытаются отключить Autovacuum, считая, что он "грузит диск". Это фатальная ошибка. Отключение приведет к неконтролируемому росту размера базы, деградации производительности и, в конечном итоге, к остановке системы для ручной очистки (которая может занять дни). Autovacuum нужно не отключать, а настраивать (делать более агрессивным).
4. Checkpointer (Контрольная точка)
Процесс, который выполняет Checkpoint — событие, при котором все грязные страницы из памяти гарантированно сбрасываются на диск, а специальные метки ставятся в журнале транзакций. Это сокращает время восстановления после сбоя: при рестарте СУБД начнет накатывать журнал не с самого начала времен, а с последней контрольной точки.
Обеспечение надежности и целостности (ACID & WAL)
Главное отличие промышленной СУБД от простой файловой системы — это гарантия того, что записанные данные не пропадут и не будут повреждены, что бы ни случилось с оборудованием (кроме физического уничтожения дисков). Эти гарантии описываются аббревиатурой ACID и технически реализуются через механизм WAL.
ACID — Четыре столпа надежности
ACID — это набор требований к транзакционной системе, обеспечивающий предсказуемость и надежность работы.
Расшифровка ACID
- A — Atomicity (Атомарность): Принцип «Всё или ничего». Транзакция, состоящая из 10 операций, должна выполниться целиком. Если на 9-й операции произошла ошибка (или отключилось питание), система должна откатить все предыдущие 8 операций, вернувшись в исходное состояние. Частичное применение изменений недопустимо.
- C — Consistency (Согласованность): Транзакция переводит базу данных из одного корректного состояния в другое. Данные всегда должны соответствовать заданным правилам (ограничениям целостности, внешним ключам). Нельзя сохранить возраст «-5 лет», если задано ограничение
age > 0. - I — Isolation (Изолированность): Параллельные транзакции не должны мешать друг другу. Результат выполнения параллельных транзакций должен быть таким же, как если бы они выполнялись последовательно, одна за другой.
- D — Durability (Долговечность): Если система подтвердила успешное завершение транзакции (ответила
COMMIT OK), то эти изменения гарантированно сохранены на энергонезависимом носителе (диске) и не будут потеряны даже в случае немедленного краха системы или отключения питания.
Именно свойство Durability (Долговечность) является самым сложным для реализации с инженерной точки зрения, так как запись на диск — это медленная операция. Решением является механизм WAL.
WAL (Write-Ahead Log) — Журнал упреждающей записи
Если бы СУБД при каждом изменении данных сразу же искала нужное место в огромных файлах данных и писала туда, система работала бы крайне медленно из-за постоянных случайных операций ввода-вывода (Random I/O).
Вместо этого PostgreSQL использует принцип «Сначала пишем в журнал, потом меняем данные».
Принцип работы:
- Журнал (WAL): Это специальный файл на диске, в который данные пишутся строго последовательно (Sequential I/O), только в конец. Это очень быстрая операция.
- Правило WAL: Прежде чем изменить любую страницу данных в оперативной памяти (Shared Buffers), СУБД обязана создать запись об этом изменении в журнале WAL и гарантированно сбросить этот журнал на диск (используя системный вызов
fsync). - Фиксация транзакции (COMMIT): Когда пользователь отправляет команду
COMMIT, PostgreSQL не бросается записывать измененные таблицы на диск. Вместо этого он дожидается, пока маленькая запись в журнале WAL, описывающая эту транзакцию, не будет физически записана на диск. Как только WAL сброшен, PostgreSQL отвечает клиенту: «Транзакция успешна». - Отложенная запись данных: Сами данные в таблицах (в файлах данных) могут быть обновлены на диске спустя секунды или минуты (фоновым процессом Writer/Checkpointer).
Восстановление после сбоя (Crash Recovery):
Если в этот промежуток (между записью WAL и записью файлов данных) сервер внезапно обесточили:
- Данные в оперативной памяти (включая несохраненные изменения таблиц) пропадают.
- При следующем запуске PostgreSQL видит, что был аварийный останов.
- Он открывает журнал WAL и начинает последовательно «накатывать» (Replay) все записи, которые успели попасть в журнал, но не успели попасть в файлы данных.
- База данных возвращается в консистентное состояние, соответствующее последней успешной транзакции.
Итог
WAL — это компромисс между скоростью работы (пишем в память) и надежностью (гарантируем сохранение на диск). Мы платим двойной записью (сначала в WAL, потом в данные) за гарантию Durability.
Объекты базы данных
Выше была описана «физика» и «механика» работы СУБД (процессы, память, файлы), то объекты базы данных относятся к логическому уровню. Это те сущности, с которыми непосредственно взаимодействует разработчик при проектировании информационной системы.
С точки зрения архитектуры, база данных — это контейнер для логических объектов. Рассмотрим ключевые из них.
| Объект (Object) | Суть и Назначение | Ключевые особенности |
|---|---|---|
| Таблица (Table) | Фундамент хранения. Главная структура реляционной БД. Состоит из строк (записей) и столбцов (атрибутов). | • Схема: Строгий набор типов данных для каждого столбца. • Constraints: Ограничения целостности (Primary Key, Foreign Key, Check, Not Null) гарантируют качество данных на уровне структуры. |
| Индекс (Index) | Ускоритель поиска. Отдельная структура данных (обычно B-Tree), которая хранит отсортированные ключи и ссылки на физическое расположение строк в таблице. | • Плюс: Ускоряет чтение (SELECT) в сотни раз (поиск за O(log N)).• Минус: Замедляет запись ( INSERT, UPDATE), так как при каждом изменении таблицы нужно перестраивать индекс.• Аналогия: Алфавитный указатель в конце книги. |
| Представление (View) | Виртуальная таблица. Это не физические данные, а сохраненный SQL-запрос, к которому можно обращаться как к таблице. | • Безопасность: Позволяет скрыть часть колонок (например, зарплату) от пользователя. • Абстракция: Упрощает сложные запросы (скрывает внутри себя 10 JOIN-ов). • Materialized View: Особый вид, который сохраняет результат запроса физически (кэширует) для ускорения тяжелой аналитики. |
| Хранимая процедура / Функция | Бизнес-логика внутри БД. Программный код (на PL/pgSQL, Python, Java), который выполняется непосредственно на сервере СУБД. | • Data Locality: Обрабатывает данные там, где они лежат, экономя сетевой трафик. • Атомарность: Позволяет упаковать сложную логику в одну транзакцию. • Триггеры (Triggers): Процедуры, автоматически запускаемые при наступлении события (например, при вставке записи). |
| Последовательность (Sequence) | Генератор чисел. Объект для создания уникальных идентификаторов. | • Гарантирует уникальность и возрастание чисел даже при параллельных транзакциях. • Используется для полей ID (Auto Increment). |
PostgreSQL — это объектно-реляционная система (ORDBMS)
Приведенный выше список содержит лишь наиболее часто используемые объекты. Важно понимать, что архитектура PostgreSQL фундаментально построена на концепции «Всё есть объект».
В отличие от классических реляционных систем, PostgreSQL позволяет пользователю расширять систему, создавая новые типы объектов, аналогично тому, как это делается в языках программирования. В системном каталоге (таблицах pg_class, pg_type, pg_proc) на равных правах регистрируются:
- Типы данных: Вы можете создать свой тип
complex_numberилиgps_point. - Операторы: Вы можете научить базу складывать эти типы знаком
+. - Агрегатные функции: Свои аналоги
SUMилиAVG. - Расширения (Extensions): Целые модули (как PostGIS), которые добавляют сотни новых объектов и логику работы с ними.
Каждому такому объекту внутри системы присваивается уникальный идентификатор — OID (Object Identifier). Для ядра СУБД таблица с миллионом строк и функция на Python — это просто две записи в системном каталоге, на которые можно ссылаться по OID.
Вывод по второму учебному вопросу
Изучение общих принципов функционирования СУБД позволяет сделать вывод, что база данных — это не «черный ящик» для простого складирования файлов, а сложнейшая инженерная система, по своему устройству напоминающая операционную систему специального назначения.
Ключевым аспектом эксплуатации является понимание процессной модели и работы с памятью. СУБД PostgresSQL, реализующая архитектуру «процесс на соединение», требует от инженера внимательного отношения к управлению пулом коннектов (Connection Pooling), так как бесконтрольное создание соединений истощает ресурсы сервера быстрее, чем выполнение самих SQL-запросов. Понимание механизма Shared Buffers и локальной памяти (work_mem) необходимо для тонкой настройки производительности: баланс между кэшированием и операциями сортировки определяет пропускную способность системы.
Второй фундаментальный вывод касается надежности. Механизмы ACID и WAL (Write-Ahead Log) демонстрируют инженерный компромисс между производительностью и сохранностью данных. Гарантия целостности (Durability) обеспечивается за счет принудительной синхронизации журнала с диском, что является естественным ограничителем скорости записи. Инженер должен осознавать, что «бесплатной» надежности не бывает, и любая оптимизация настроек (например, отключение синхронного коммита) всегда несет в себе риски потери данных при сбоях.